<r>Master Ripples Walkthrough: Your Step-by-Step Guide to Flawless Model Deployment and Operational Mastery</r>
Dane Ashton
3523 views
Master Ripples Walkthrough: Your Step-by-Step Guide to Flawless Model Deployment and Operational Mastery
Navigating the complexities of Ripples—Tiny-Compute models with outsized potential—can feel overwhelming, but Ripples Walkthrough transforms the process into a seamless, intuitive journey. This comprehensive guide traces every critical phase, from initial setup through deployment, monitoring, and troubleshooting, equipping developers and engineers with actionable insights and best practices used by industry leaders.
In today’s fast-paced AI landscape, Riccules stands out not for raw power alone, but for elegant efficiency—delivering real-time inference on edge environments with minimal latency. Yet harnessing its full capability demands more than passive user access.
Why a Structured Walkthrough Matters for Ripples
Every deployment journey shares core stages, yet success hinges on disciplined execution. Ripples Walkthrough eliminates guesswork by mapping each phase with precision, ensuring teams avoid costly missteps in model integration, resource allocation, and performance tuning. The result is faster time-to-value, reduced operational friction, and sustainable scalability.
The walkthrough is meticulously tailored to real-world workflows, beginning with model import and validation—step one crucial for confirming compatibility across versions and architectures. Developers learn to verify input pipelines, ensuring data formats align perfectly with Ripples’ requirements. This early checkpoint prevents mid-deployment failure, saving days of rework.
From configuration to prediction, each stage follows a deliberate sequence.
Engineers benefit from clear, modular workflows: modifying environment variables via | Configuring Model Parameters and Runtime Settings Modern AI deployment thrives on customization. Ripples Walkthrough guides users through setting environment variables with intuitive flags—from enabling GPU acceleration | Optimizing for Edge Efficiency Ripples excels in resource-constrained environments. The walkthrough teaches strategic tuning of floating-point precision, batch size, and memory allocation to maximize throughput without sacrificing inference speed.
Techniques like quantization and pruning are demystified with practical examples, demonstrably improving client-side performance. For edge deployments, even minor tweaks can yield exponential gains. By analyzing latency thresholds and memory footprints, teams align model behavior with real-world device constraints.
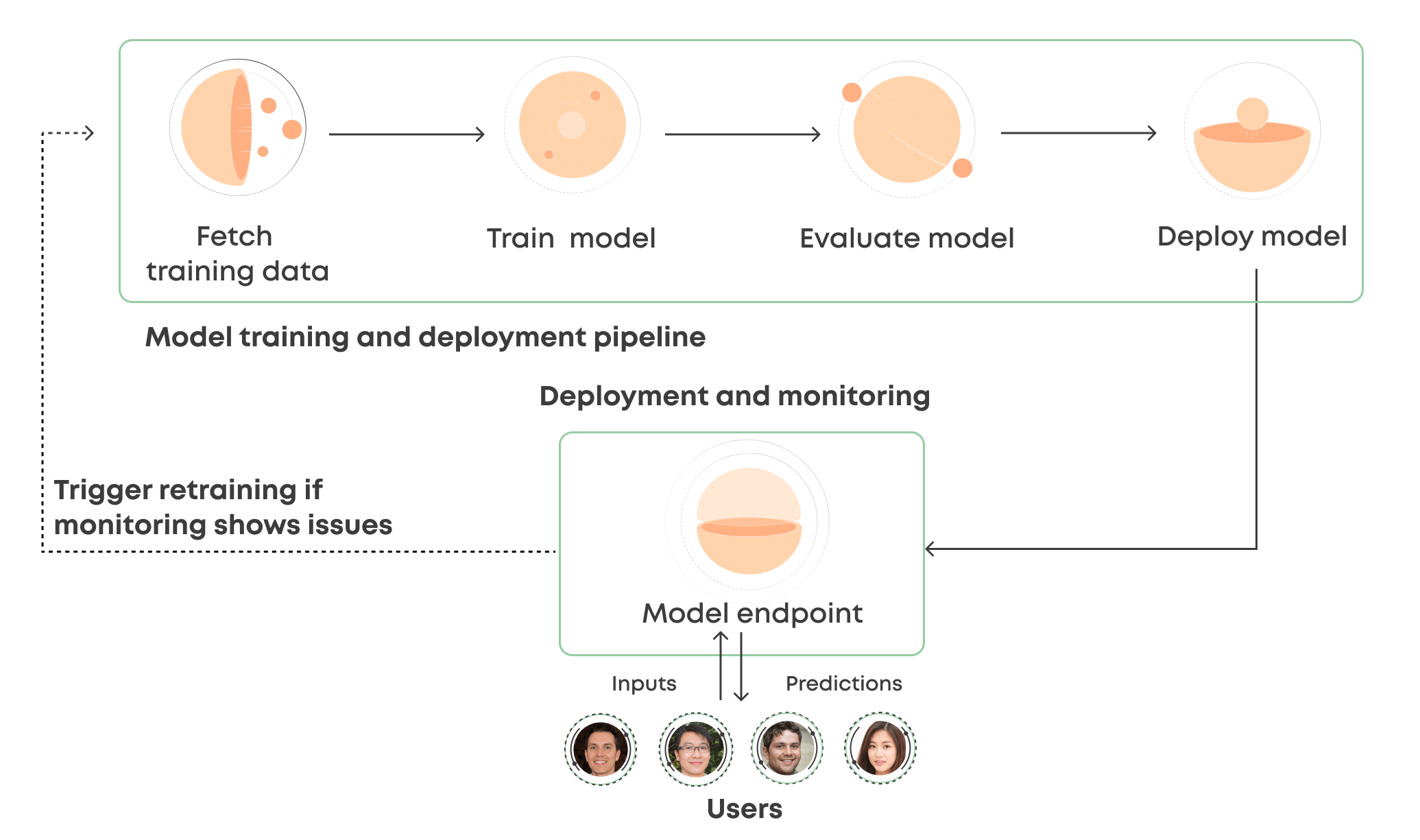
Monitoring and Analytics: Keeping Ripples Reliable in Production
Deployment marks only the beginning—continuous monitoring ensures long-term reliability. The walkthrough introduces lightweight observability tools embedded within Ripples that track inference latency, request throughput, error rates, and resource utilization.
Developers learn to interpret dashboards, set up early-warning alerts, and correlate performance dips with system events.
With custom logging and error handling patterns shared throughout the guide, teams gain the tools to diagnose latency spikes or data drift proactively. Case studies reveal how timely intervention prevented outages in high-traffic applications, preserving user trust and uptime.
Advanced telemetry transforms raw metrics into actionable insights, turning passive monitoring into a strategic advantage.
Building Resilience Through Smart Debugging Even minor bugs can disrupt edge AI services. The walkthrough emphasizes structured debugging workflows—leveraging console logs, model versioning controls, and fallback mechanisms—ensuring rapid recovery. By following scripted troubleshooting steps, developers identify root causes faster than traditional alter-and-pray methods.
Real-World Implementation: From Demo to Production-Ready Iteration
Practical application separates theoretical understanding from operational success.
The Ripples Walkthrough showcases end-to-end deployments across diverse use cases—ranging from intelligent IoT edge devices to real-time language processing systems. Each scenario emphasizes environment-specific optimizations, from region-based latency mitigation to personalized model fine-tuning via lightweight retraining tools built into the platform.
One enterprise client reportedly reduced deployment cycles by 60% using the walkthrough’s iterative feedback loops, where incremental testing and performance benchmarking become standard practice.
Others leverage versioned model packaging and automated rollback strategies learned from the walkthrough, maintaining deployment stability even during rapid iteration.
The journey through Ripples, guided step by step, reveals not just *how* to deploy—but how to sustain excellence. By integrating disciplined configuration, rigorous monitoring, and adaptive debugging, teams unlock Ripples’ true potential: combining precision engineering with operational agility. In an era where edge AI drives innovation across verticals, mastering this walkthrough is no longer optional—it’s essential.
With structured execution and data-informed decision-making, Ripples transitions from a development curiosity to a production force multiplier, delivering reliable, scalable AI impact—one walkthrough at a time.




/south-carolina-state-county-map-165047526-58b9dacd3df78c353c4410c6.jpg)



